PII issues
Nanitor supports scanning for credit card or social security number information.
Credit Cards and social security numbers are considered to be part of Personal Identifiable Information (PII). When the Nanitor agents detect a file that possibly contains credit card or social security number information it will raise an issue of the type PII in Nanitor.
Enabling the PII scanner
Before you can use the PII functionality of Nanitor you will need to enable the PII scan functionality. The functionality can be limited to a subset of assets. The scan for social security numbers can be dis-/enabled as part of the PII solution. Social security numbers are supported for the UK, the USA, and Iceland.
As a Nanitor administrator navigate to Organization Management -> PII
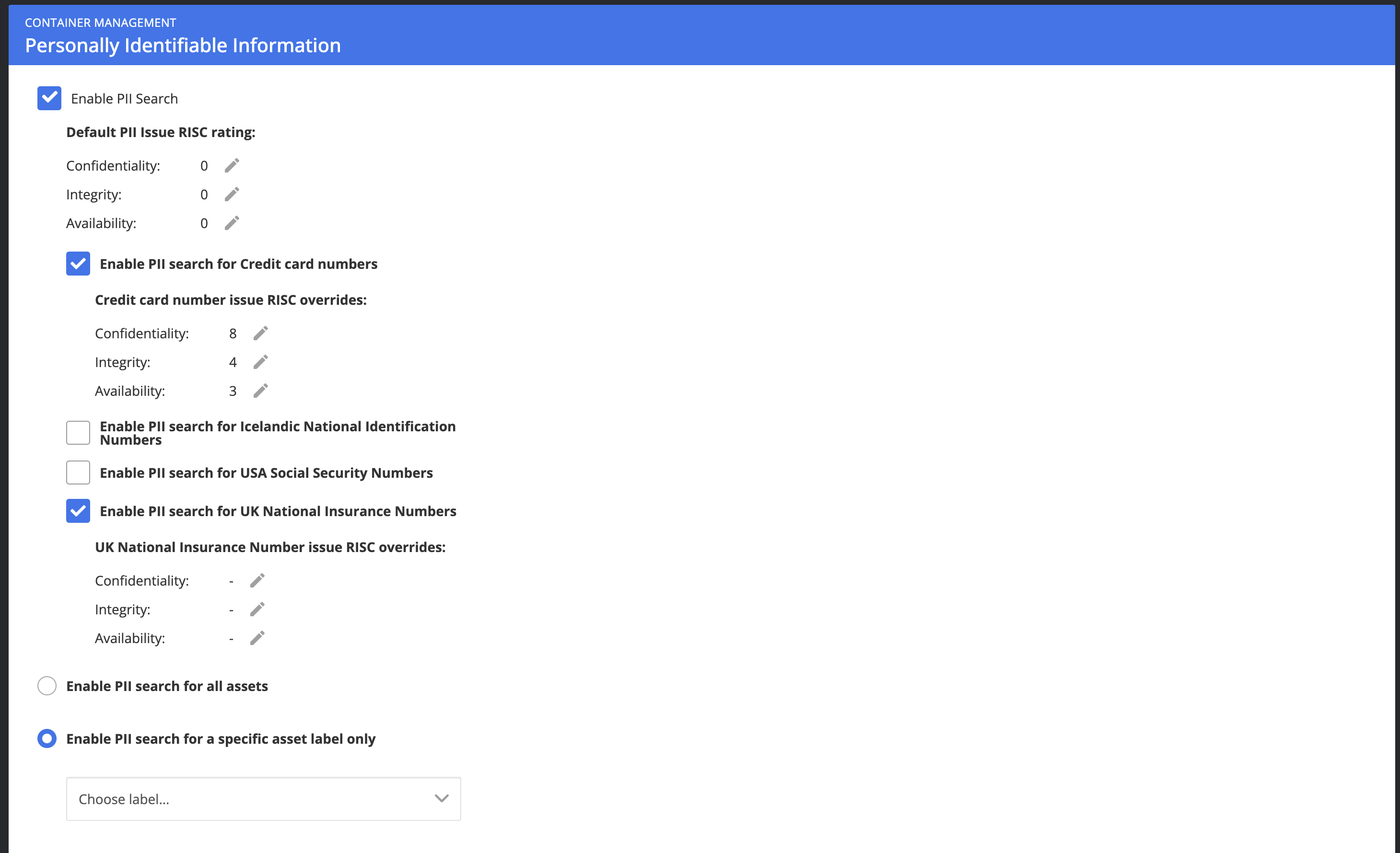
- The PII feature can be enabled globally or on track PII issues for certain labels.
- The PII feature can include discovering possible flagged national security numbers (support for the UK, USA, and Iceland)
- You can set the default Issue priority rating for a PII issue. PII issues can have a different priority rating than PII issues for credit card information
Once this is applied, a flag is applied to all devices that indicate that a PII search will be conducted.
PII scans performed by the agent
The agent periodically scans for PII. By default, this happens every 20 minutes. On each such iteration, it will:
- Scan the list of already found PII items. So if an issue is resolved, it will be detected within 20 minutes.
- Continue crawling the file system from where it left off on the previous iteration. It will go through 2000 file system entries by default on each iteration.
The process is designed for a low footprint:
- 1 iteration every 20 minutes only.
- Sleep between each directory is processed
- The Agent runs with priority “Below Normal” (Windows) to ensure the user is never bothered and will never feel any effect from the scanning
Once the agent completes a full scan of the system drives, it waits for 7 days until the next scan/crawl starts. However, it always keeps continuously rechecking existing PII issues such that if the PII is removed, it will be reflected in the Nanitor UI.
The search process uses a smart I/O and buffering scheme to minimize the memory usage. Files under 50 MB it will not be read again unless the MD5 hash of the file or file size has changed. If the file is larger it is only checked if the size has changed.
All found PII information is masked and not stored in the Nanitor database.
The asset detail page will indicate if the PII search is enabled for a device.
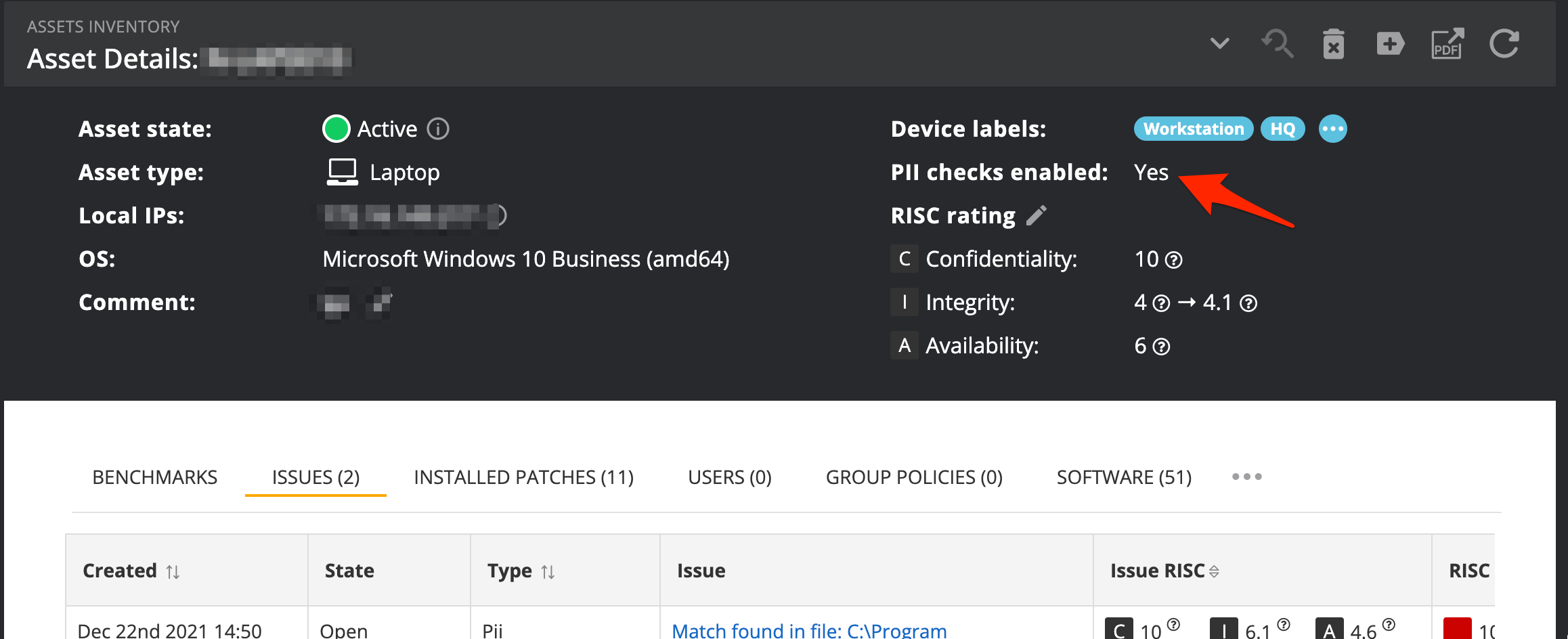
Supported Platform and file formats
The PII scanner is supported on the following platforms. The PII scan is a feature of the agent distributed on the device. The list below is also showing existing limitations to the scanner.
| Platform | Location |
|---|---|
| Windows | System drive only (typically C:) |
The PII scan engine is built into the agent. Assigned devices automatically download an additional program that can read formats such as DOCX, XLSX, and PDF formats. The support thus covers:
- Any text files including TXT, JSON, XML
- DOCX
- XLSX
- ZIP archives
Files with unknown binary formats will be skipped.
PII Issues
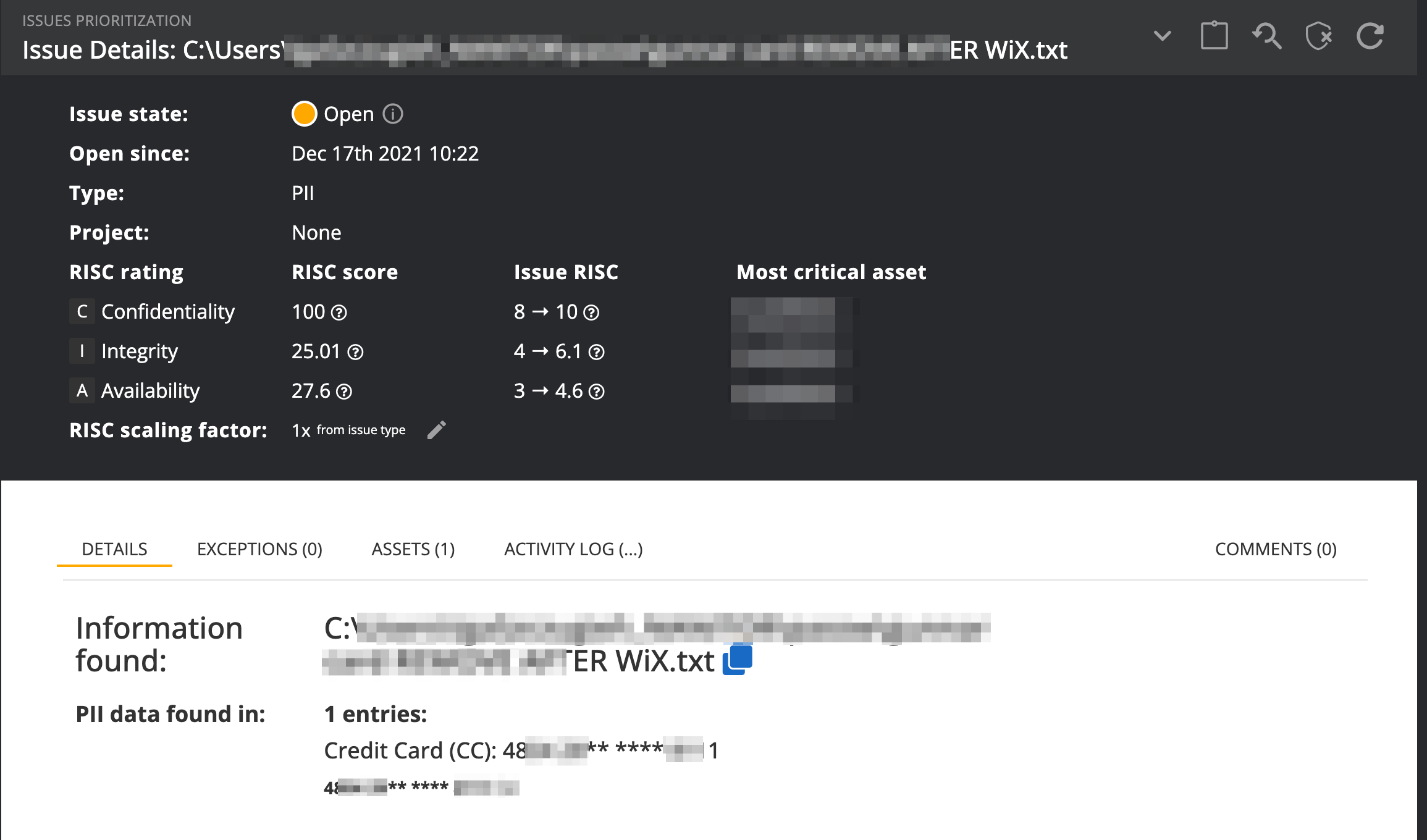
Issues detected from the PII scanner will be displayed in the Nanitor issue list and are categorized with the PII issue type.

The PII issue details are similar to other issues in Nanitor. You will see information about the file name and an extract of what Nanitor discovered in that file.
Exceptions
Similar to other issue types you can create exceptions for specific detected PII issues. A PII issue is normally only detected once. But since there might be false positives you can also create PII exceptions on a more global level. These exceptions can be made from Organization Management -> PII ignore list.
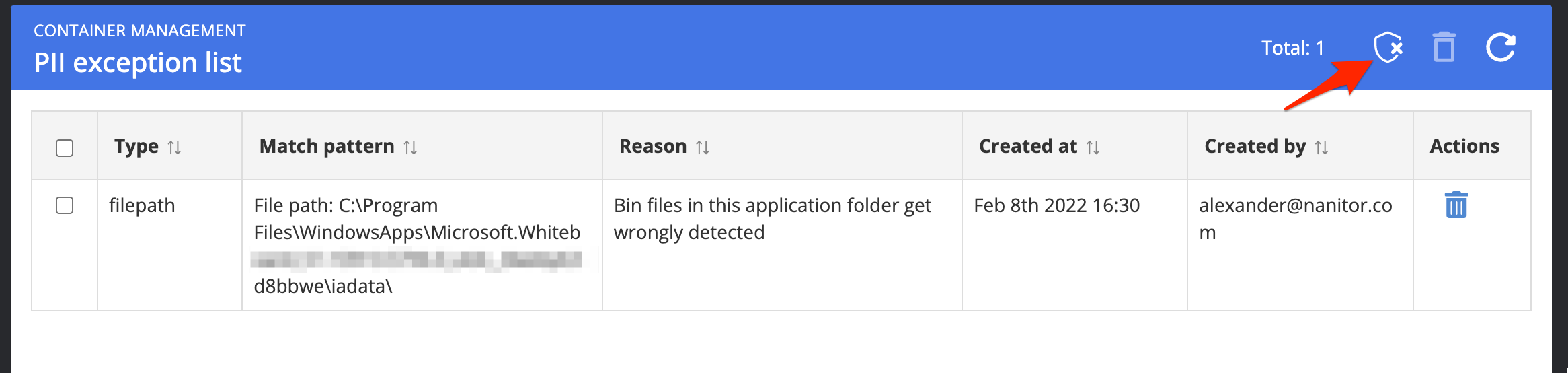
Clicking on the exception icon on the top right will give you the option to create a new PII exception.
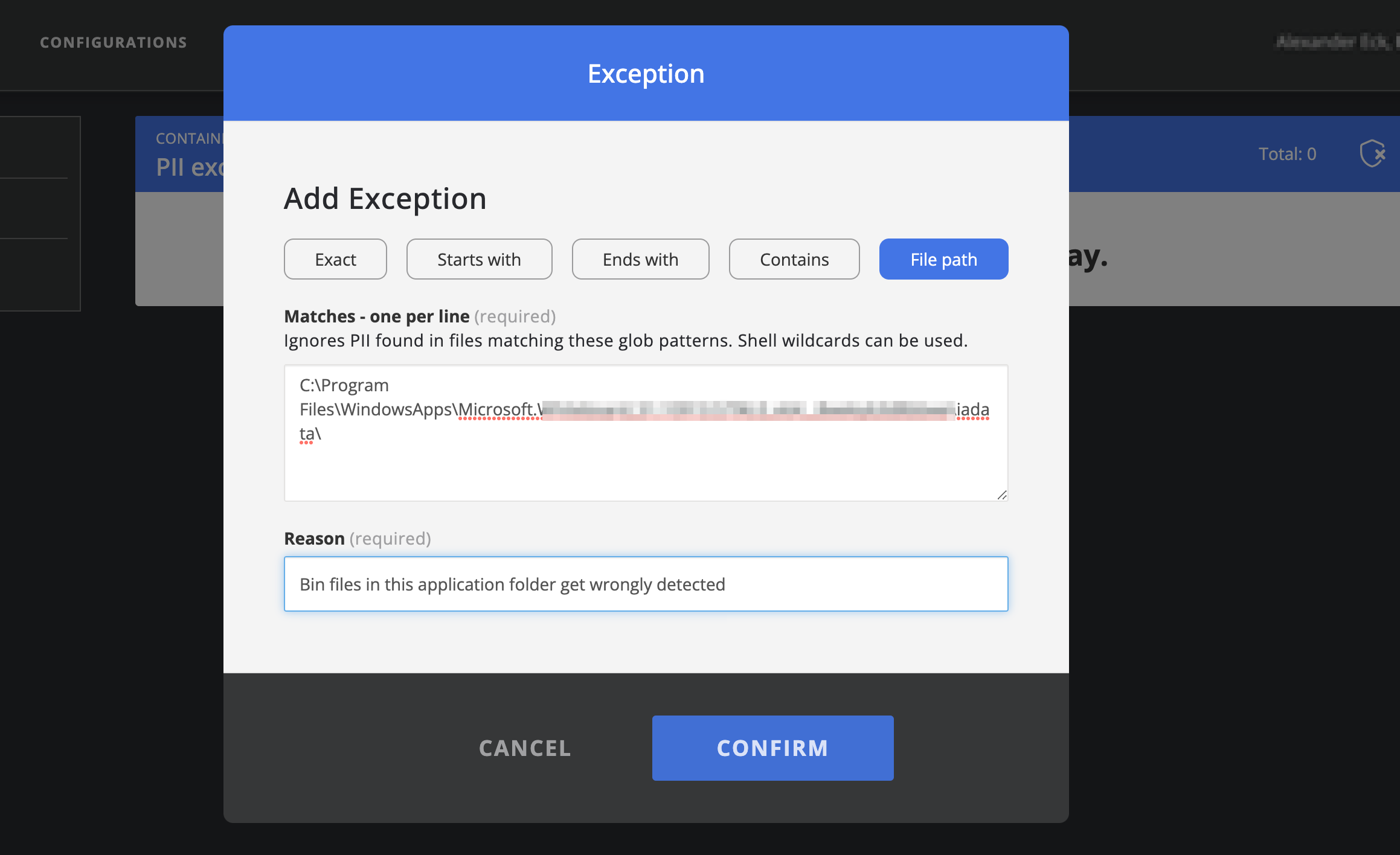
Exceptions can be made e.g. for file paths, exact file names, or file/folder names with a certain beginning or end.